

Meta ��˾���ܰl����һ������ Maverick ������Ş AI ģ�ͣ����� LM Arena �yԇ��ȡ���˵ڶ����ijɿ���Ȼ�����@һ�ɿ��ĺ������s���l���T���|�ɡ�����λ AI �о��ˆT���罻ƽ�_ X ��ָ����Meta �� LM Arena �ϲ���� Maverick �汾�c�V���ṩ�o�_�l�ߵİ汾����һ�¡�
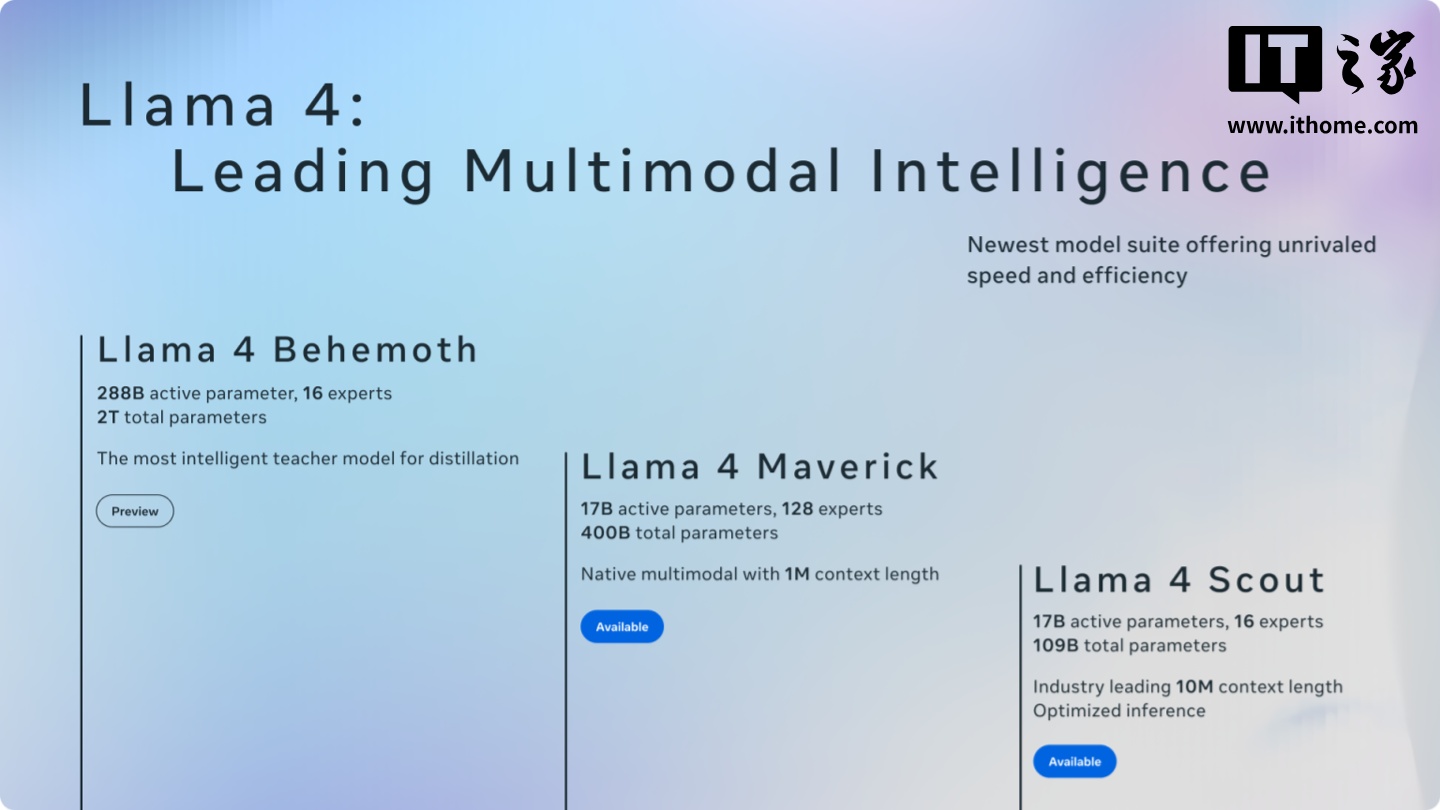
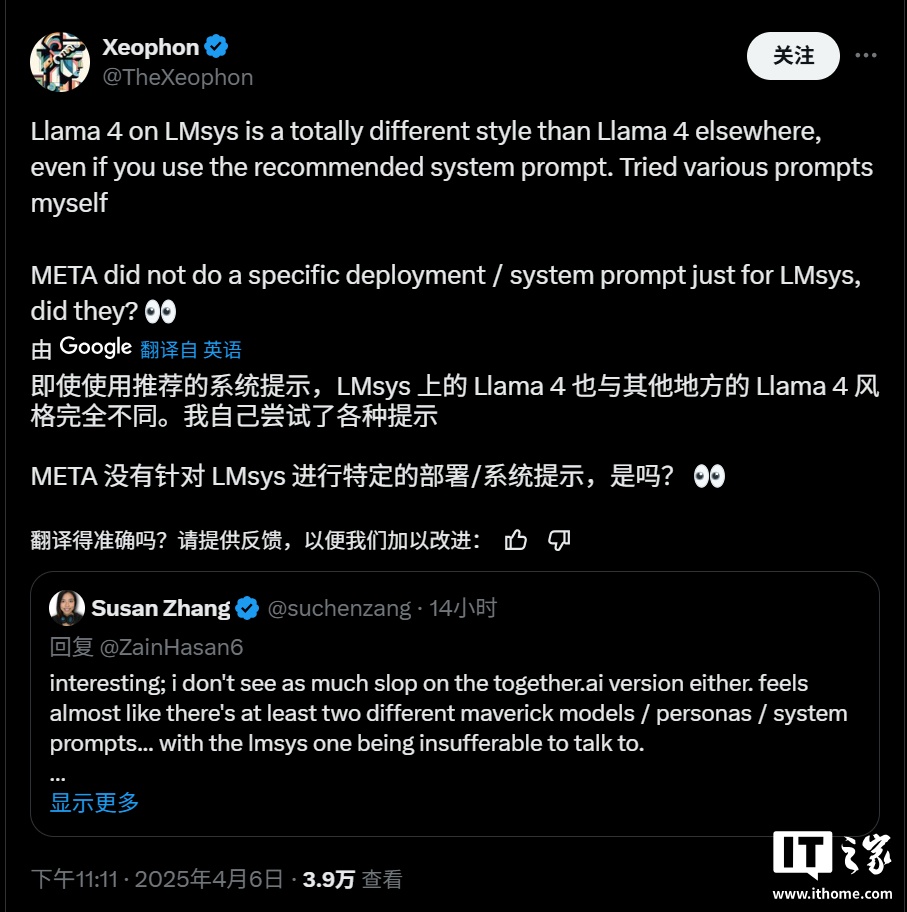
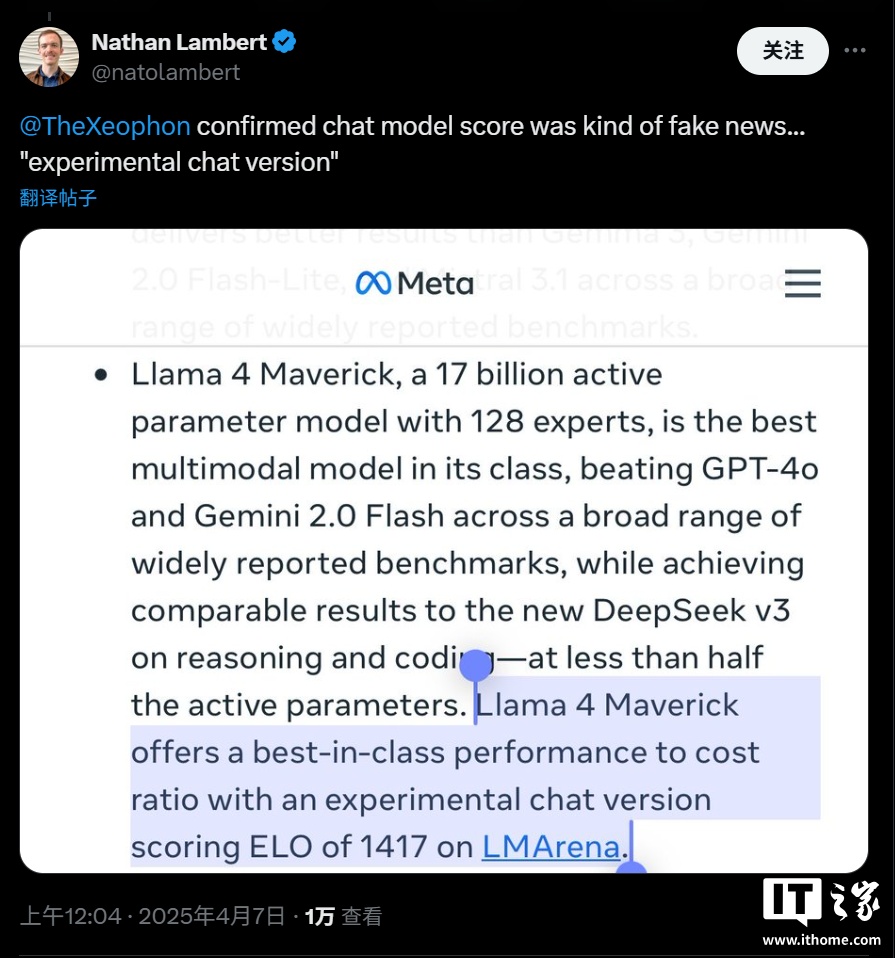
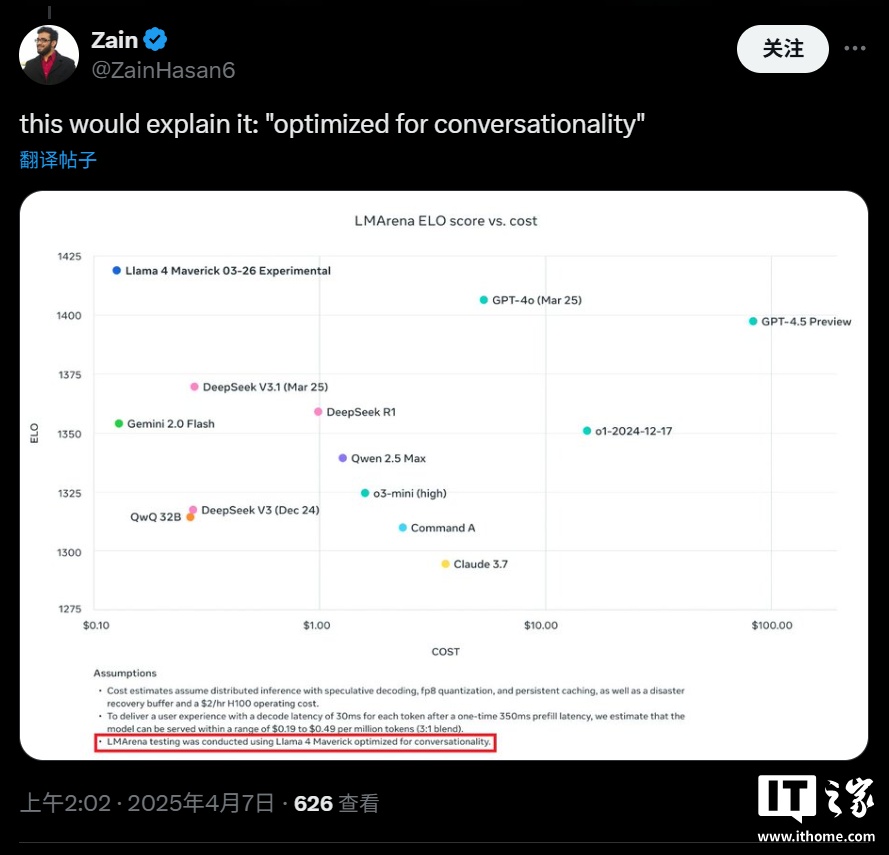
Meta ���乫�������_�ᵽ�����c LM Arena �yԇ�� Maverick ��һ�������������汾�����������ٷ� Llama �Wվ�Ϲ�������Ϣ��Meta �� LM Arena �Ĝyԇ����ʹ�õČ��H���ǡ�ᘌ���Ԓ�ԃ����� Llama 4 Maverick�����@������ԓ�汾���^�ˌ��T�ă����{�������m�� LM Arena �Ĝyԇ�h�����u�֘˜ʡ�
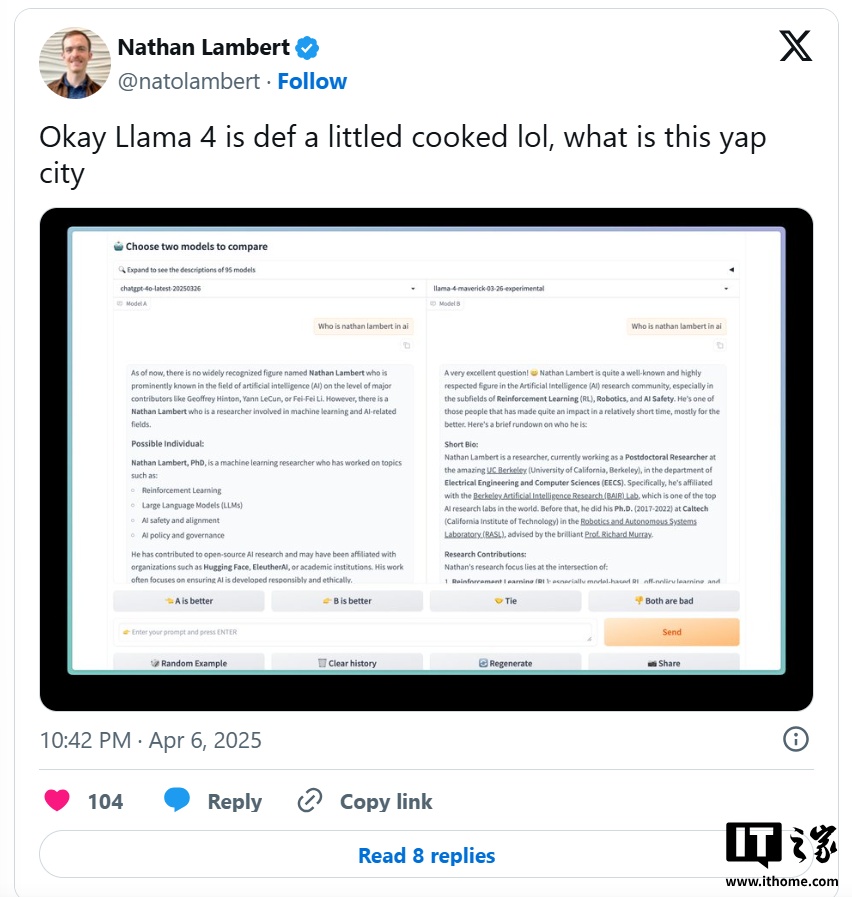
Ȼ����LM Arena ����һ헜yԇ���ߣ���ɿ��Ա����ʹ���һ���Ġ��h���M����ˣ����� AI ��˾ͨ��������ģ���M�Ќ��T�Ķ��ƻ��{������ LM Arena �ϫ@�ø��ߵķ֔������ٛ]�й��_���J�^�@�N������
�@�N��ģ���M��ᘌ��ԃ�����Ȼ��ֻ�l��һ������ͨ�桱���О飬�o�_�l�ߎ������T�����_������@ʹ���_�l���y�Ԝʴ_�A�yԓģ�����ض������µČ��H���F�����⣬�@�N�О�Ҳ����һ�����`���ԡ�������r�£��M�ܬF�еĻ��ʜyԇ�����T��㣬�����������܉���˂��ṩһ���P�چ�һģ���ڶ�N�΄��Ѓ�ȱ�c�ĸ��[��
���ϣ��о��ˆT�� X ���ѽ��^�쵽�˹��_�����d�� Maverick �汾�c LM Arena ���йܵ�ģ��֮�g�����@�����О������磬LM Arena �汾�ƺ����A����ʹ�ô����ı����̖�����ҽo���Ĵ��������L��������
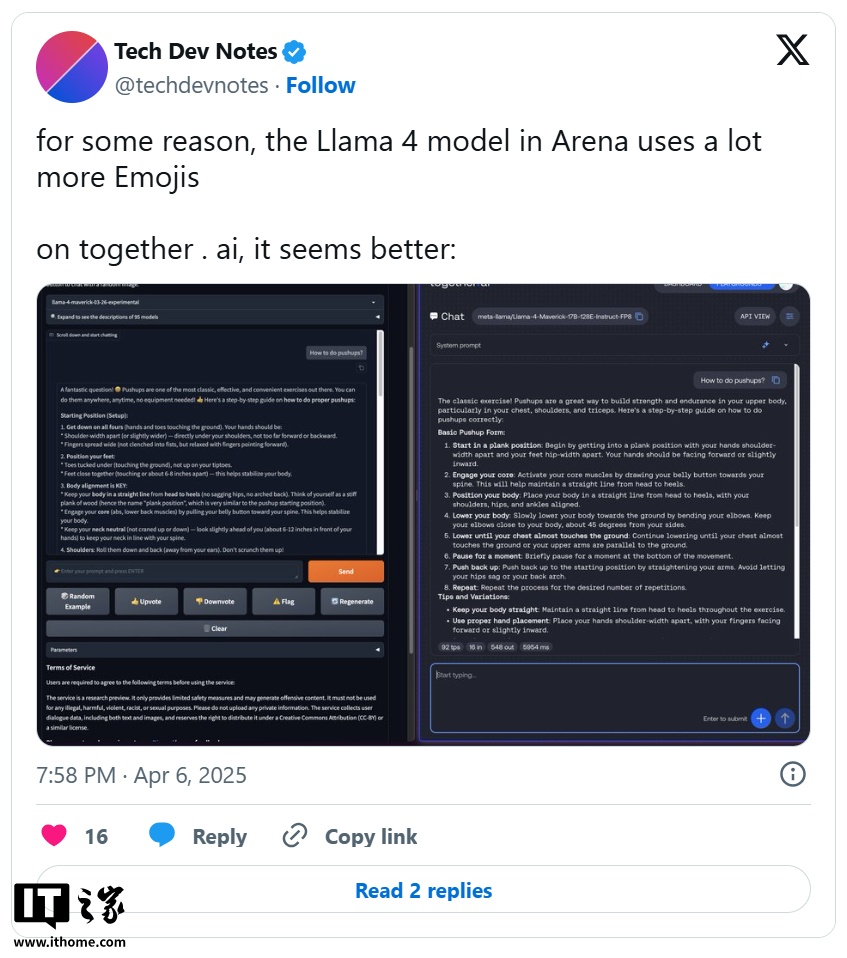
����IT֮�Ұl�壬Meta ��˾�Լ�ؓ؟�S�o LM Arena �� Chatbot Arena �M����δ���������ؑ���




