

2025 �� 8 �� 4 �գ�ȫ������� AI ���ܻ����u�y�M�� MLCommons® ��ʽ�l������һ݆ MLPerf® Storage v2.0 ���ʜyԇ�Y���������Ї��Ĵ惦�S�����ڿƼ��ڴ˴Μyԇ�б��Fͻ������ȫ�W�惦һ�w�C F9000X ���H��ȫ��ģ�͜yԇ�������I�ȣ����������c�惦��Ⱥ 513GB/s �Ŀ�����ˢ�� 3D-Unet ģ�͜yԇ�ļo䛣���� MLPerf ȫ�����ܰ�Ρ�
MLPerf Storage��AI �惦���ܵ��S������˜�
MLCommons ����ȫ���˹����ܹ����ˣ�ʼ�K������Ҏ�� AI ���g�Ĝʴ_�ԡ���ȫ�ԡ��ٶ��cЧ���u�����Ƅ� AI ϵ�y���܃�����������Եõ�ȫ��I��V���J�ɡ��� MLPerf Storage Benchmark ����ԓ�ˌ��� AI ��������Ĵ惦���ʜyԇ��ͨ�^ģ�M�挍 AI Ӗ���е� I/O ���������ʺ����惦ϵ�y�� GPU ݔ��Ӗ���������ٶ��c������
�˴ΰl���� MLPerf Storage v2.0���� v1.0 ���A���Mһ�������������� 3D-Unet��ResNet50��CosmoFlow ����Ӗ��ģ���⣬���� Checkpoint ����ؓ�d����ȫ�渲�wӖ���Д��c�֏͡�ģ�ʹ�n�Ȍ��H��������_���Y���ć�֔���c�����ԣ�v2.0 Ҫ��ÿ헻��ʜyԇ��횶���؏͈��У�Ӗ���΄� 5 �Ρ�Checkpoint �΄� 10 �Σ�����ȫ���B�m�\�Пoʧ����ͬ���ύ�����yԇ��־����K�Y��ȡ����\�е�ƽ��ֵ ���� �@һϵ�Ї���Ҏ����ʹ��ɞ�I����� AI �惦���ܕr��߅����rֵ�ę����˜ʡ�
����ȫ�Wˢ��ȫ��o� ��СҎģ��Ⱥ���ܵ�һ
MLPerf Storage ���ʜyԇ��֧�ֆ�Ӌ�㹝�c���͑��ˣ��\�ж��� ACC��GPU ����������ģ�͜yԇ��Ҳ�m��ֲ�ʽӖ����Ⱥ���� ���� ͨ�^��͑���ģ�M�挍���������L���惦��Ⱥ����ָ��w�Ćι��c���ֲ�ʽ��Ⱥ��ȫ���� AI ����ؓ�d�������P�I�ĺ����˜ʣ����ڱ��C������ GPU �����ʣ�3D-Unet �c ResNet50 ģ���� 90%��CosmoFlow ģ���� 70%����ǰ���£��惦ϵ�y���܌��F�ľۺώ������@�ָ���Ǻ����惦ϵ�y���H�����ĺ��ģ�ֱ���w�F���� AI Ӗ���^�����Ƿ��܉��֡�ι�Ӌ���YԴ��������� GPU ���e���M��
���yԇ�Y���@ʾ���� 3D-Unet��ResNet50 �Լ� CosmoFlow ����ģ�͵Ĝyԇ�����£���ͨ��Ӳ���h���У�ᘌ��ֲ�ʽ�惦����СҎģ��Ⱥ���������c�惦��Ⱥ������ȫ�W F9000X ��ȫ��֪���ֲ�ʽ�惦�S����Ó�f��������Ⱥ���������P�Iָ��λ��ȫ���һ���������� 3D-Unet ģ�͜yԇ�У���Ⱥ�����_�� 513 GB/s ���������ѹ����Y���е����ֵ��
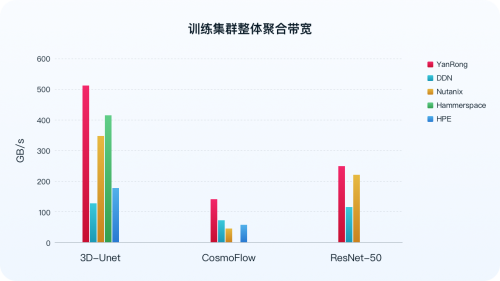
������Դ��MLCommns �ٷ� https://mlcommons.org/benchmarks/storage/
���ֲ�ʽ�����⣬�چο͑��˜yԇ�У�����ȫ�W F9000X ͬ��չ�F���������ܣ��Mһ����C�����ڲ�ͬ����Ҏģ�µď��Ŕ���̎��������
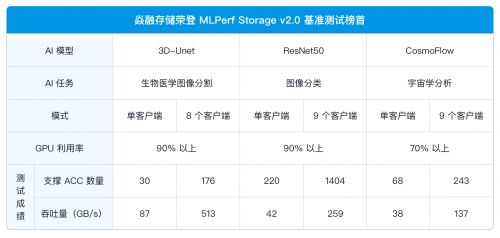
���⣬�������� Checkpoint ����ؓ�d�yԇ�У�ᘌ� Llama3-70B ģ�͈�����ͨ�^���� 8 ���͑���ģ�M���lՈ���� 64 ��ģ�M GPU �h�������F 221 GB/s �xȡ�����c 79 GB/s ���뎧���ĸ����ܱ��F���@�N�����Ҹ�Ч�Ď���֧���������܉ʱ��� Checkpoint �ļ���ģ��Ӗ��ȫ�����Ќ��F�뼉�O���x�����ĵӴ惦����� AI Ӗ���΄յĔ��c�mӖ�B�m���cģ��Ӗ�����������μ��g������������I���ݑ�����Ҏģģ��Ӗ���ć����惦����
���ڴ惦 MLPerf �yԇ���F�����g�e���c���B�fͬ���P�I
���˽⣬���ڴ惦ȥ��ㅢ�c�� MLPerf Storage v1.0 ���ʜyԇ�����Գ�ɫ�ɿ���ȫ��֪���惦�S���Џ���ͻ�������ڴ惦֮�������� MLPerf �惦���ʜyԇ�г��mȡ�Ã����ɿ��������������L����� AI ��ģ��Ӗ���c�����Ⱥ��Ĉ����ļ��g�e�ۣ�һ���棬ͨ�^�L�������ģ��Ӗ���c�����Ⱥ��Ĉ������������ AI ����ؓ�d���ԣ���һ���棬�ļܘ��OӋ��ܛӲ��ȫ���g�������m���Mϵ�y�Ԅ����c�����������𑪌�������ؓ�d�ĺ���������
�c��ͬ�r������Ҳ�c NVIDIA��Intel�����A����H3C�������ㄓԴ��Memblaze����������DapuStor�������������B���չ�_��ȅfͬ���ھW�j��оƬ����������SSD ���P�I�h���o�ܺ��������FܛӲ��������m���c�O��������Ч����ϵ�y�� AI ���A�Oʩȫ�·�еĸ�Ч�����\�С�
���_�Y���@ʾ������ȫ�W�惦���������еĸ����ֲܷ�ʽ�ļ�ϵ�y YRCloudFile��ͨ�^����P�I���g���F����ͻ�ƣ�
�������� Multi-Channel �W�j�����ۺϼ��g�������϶��� InfiniBand/RoCE �W�����ܣ��ڴ� IO �����³��ጷ�Ӳ��������֧�γ����ٔ�����ݔ��
ϵ�y�߂�ؓ�d��֪�������ɸ������������ГQ�Д��c݆ԃģʽ����Ч���� IOPS ���ܣ�
�� IO ģ�͌��棬ͨ�^�����������OӋ�p���������ГQ����������̎����������ͨ�^̎���������YԴ�ĸ�Ч���䣬���;����{���_�N��֧�θ߲��l����̎����ͬ�r����ְl�] NVMe SSD �����܃��ݣ�
ᘌ���Ҏģ GPU ��Ⱥ�׳��F�ľW�j�������}����헃�����ݔ�C�ƣ����ϔ�����ݔ�ĸ�Ч�c������
�S����ģ����ǧ�|���f�|�������M���惦�����֧�ε�����Ҫ����m�������˴����ڿƼ��� MLPerf Storage v2.0 �еı��F�����Hӡ�C���Ї��惦�S�̵ļ��g������Ҳ�� AI ���A�Oʩ�����܃����ṩ�˿Ʌ����Č��`·�����I���AӋ��δ���惦ϵ�y�ĸߎ����������t������Ȼ�� AI ��ģ�͏V����ص��P�I������֮һ��








